Harnessing the power of speech-to-text technology can revolutionize the way we communicate, document, and interact with various applications. In this blog post, we will guide you through the process of creating a simple yet effective Node.js application that leverages OpenAI’s Whisper API to record and transcribe audio in a single step.
Whether you’re a seasoned developer or just starting your journey in the world of programming, this tutorial is designed to be straightforward and easy to follow. We’ll walk you through the process of setting up a new Node.js project, installing necessary dependencies, implementing the application logic, and finally, running the application.
By the end of this post, you’ll have a solid understanding of how to record and transcribe audio using Node.js and OpenAI’s Whisper API, and you’ll be well-equipped to explore the exciting possibilities that speech-to-text technology can bring to your projects. So, let’s dive right in and start building our application!
Create A New Node.js Project
Let’s start the new Node.js project by using the following commands:
mkdir node-record-transcribe
cd node-record-transscribe
npm init -y
touch app.js
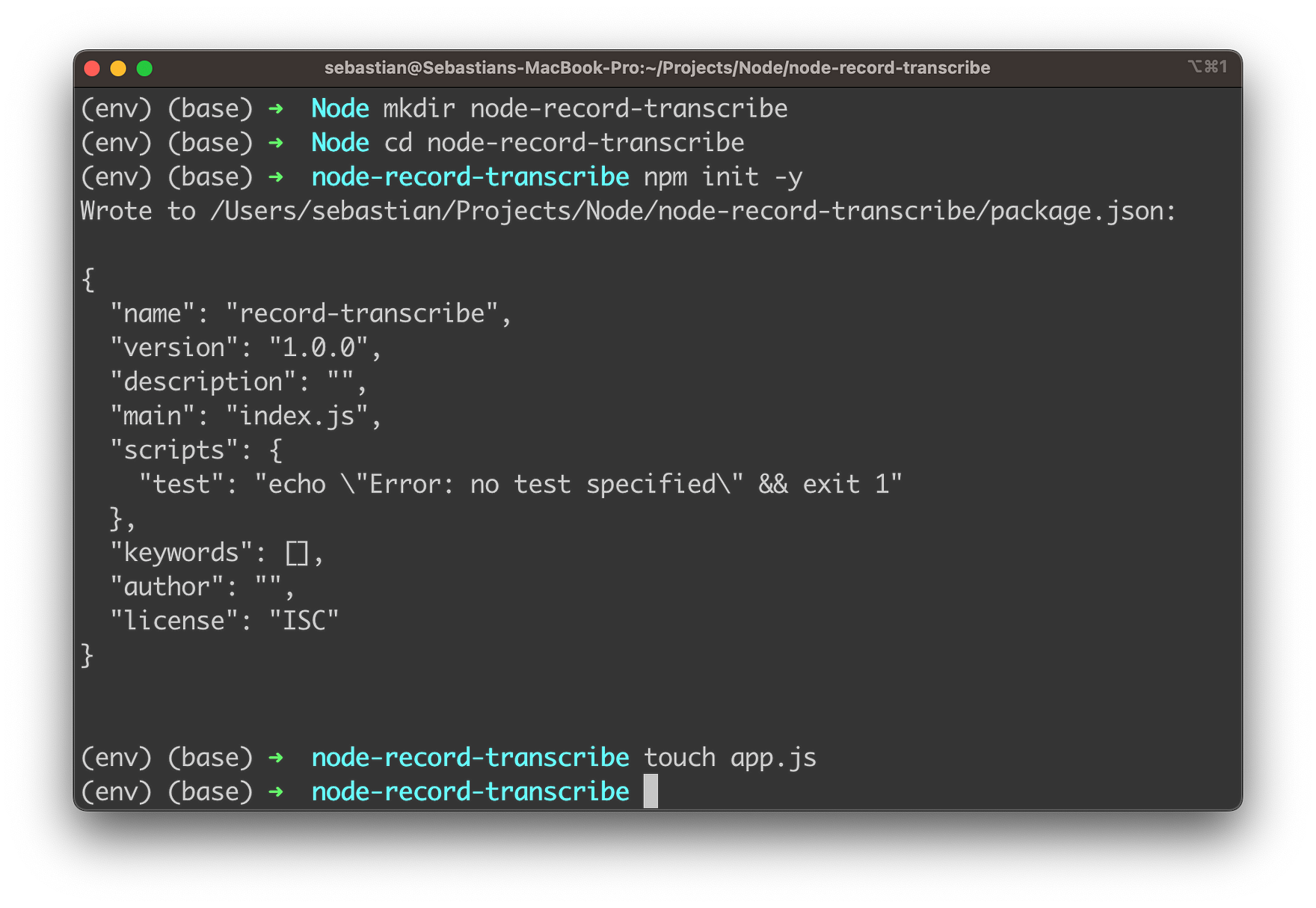
These command-line commands are used to create and set up a new Node.js project for the audio recording and transcription application:
mkdir node-record-transcribe: This command creates a new directory namednode-record-transcribe. This directory will be used to store all the files related to the Node.js project.cd node-record-transscribe: This command navigates to the newly creatednode-record-transcribedirectory. All the following commands will be executed inside this directory.npm init -y: This command initializes a new Node.js project by creating apackage.jsonfile in the current directory. The-yflag automatically sets the default values for the project configuration, skipping the interactive setup process. Thepackage.jsonfile is used to manage the project’s dependencies, scripts, and other configurations.touch app.js: This command creates a new file namedapp.jsin the current directory. This file will serve as the entry point for the Node.js application, where you’ll write the code for recording and transcribing audio using OpenAI’s Whisper API.
With this project in place, we’re ready to install needed dependencies:
npm install openai @ffmpeg-installer/ffmpeg fluent-ffmpeg mic
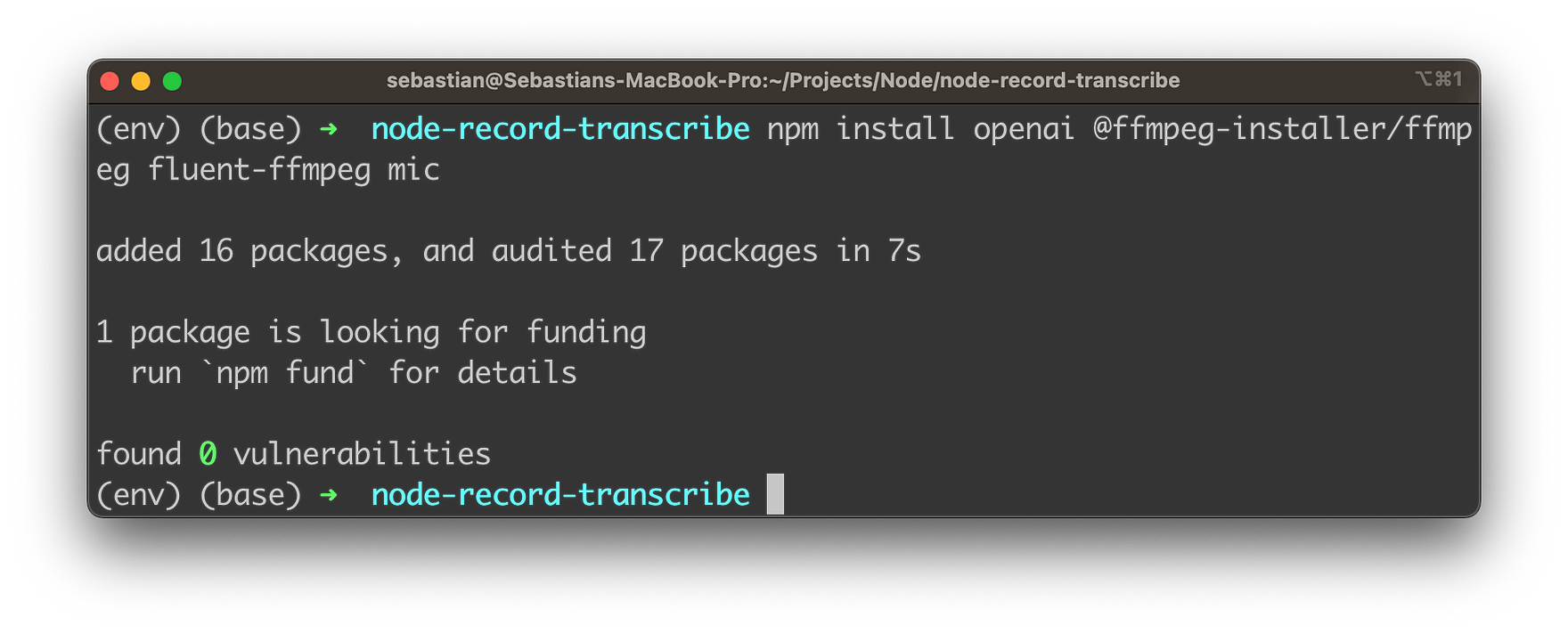
This command installs the required Node.js packages (dependencies) for the audio recording and transcription application using OpenAI’s Whisper API. Here’s a brief description of each package:
openai: This is the official OpenAI Node.js package that provides an easy-to-use interface to interact with OpenAI’s API, including the Whisper Speech-to-Text API. By installing this package, you can easily access the Whisper API for transcribing audio files.@ffmpeg-installer/ffmpeg: This package provides an FFmpeg binary, which is a popular multimedia framework for handling various audio and video formats. The package ensures that the correct FFmpeg binary is installed for your operating system. It will be used in conjunction withfluent-ffmpegfor working with audio files.fluent-ffmpeg: This package is a fluent API to work with FFmpeg, the multimedia framework. It provides a convenient and easy-to-use interface for handling audio and video processing tasks, such as converting formats, extracting metadata, and more. In this project, it can be used for processing the recorded audio before sending it to the Whisper API.mic: This package is a simple and lightweight module for recording audio using a microphone in a Node.js application. It provides a straightforward interface for accessing the system’s microphone and capturing audio input, which will be used for recording the user’s voice in this project.
By running the npm install command followed by these package names, you’re adding these dependencies to your package.json file, making them available to use in your Node.js application.
Furthermore we need to install the SoX package:
brew install sox
This command is used to install the SoX (Sound eXchange) audio processing software on macOS systems using the Homebrew package manager. SoX is a powerful command-line utility that can be used to convert, process, and play various audio file formats.
Implementing The Application Logic
Let’s use app.js to add the main logic of our Node.js application:
Step 1: Import required modules
const fs = require("fs");
const ffmpeg = require("fluent-ffmpeg");
const mic = require("mic");
const { Readable } = require("stream");
const ffmpegPath = require("@ffmpeg-installer/ffmpeg").path;
const { Configuration, OpenAIApi } = require("openai");
Step 2: Set your OpenAI API key
Replace YOUR_OPENAI_API_KEY with your actual OpenAI API key:
const configuration = new Configuration({
apiKey: "YOUR_OPENAI_API_KEY",
});
const openai = new OpenAIApi(configuration);
Step 3: Configure FFmpeg
Set the FFmpeg path using the @ffmpeg-installer/ffmpeg package:
ffmpeg.setFfmpegPath(ffmpegPath);
Step 4: Create the recordAudio function
This function handles audio recording using the mic package. The audio will be saved to the specified filename.
// Record audio
function recordAudio(filename) {
return new Promise((resolve, reject) => {
const micInstance = mic({
rate: '16000',
channels: '1',
fileType: 'wav',
});
const micInputStream = micInstance.getAudioStream();
const output = fs.createWriteStream(filename);
const writable = new Readable().wrap(micInputStream);
console.log('Recording... Press Ctrl+C to stop.');
writable.pipe(output);
micInstance.start();
process.on('SIGINT', () => {
micInstance.stop();
console.log('Finished recording');
resolve();
});
micInputStream.on('error', (err) => {
reject(err);
});
});
}
The function accepts one parameter, filename, which specifies the name of the file where the recorded audio will be saved. Here’s a breakdown of the function:
- The function returns a new Promise that will either resolve or reject based on the success or failure of the recording process.
- A new
micInstanceis created using themicpackage with the specified configuration: a sample rate of 16,000 Hz, one audio channel (mono), and a file type of WAV. - The
micInputStreamis obtained from themicInstanceusing thegetAudioStream()method. - A writable stream,
output, is created using thefs.createWriteStream()method with the providedfilename. - A
Readablestream is created and wrapped around themicInputStream, resulting in thewritablestream. - The
writablestream is piped to the output stream, effectively connecting the microphone input to the output file. - The
micInstancestarts recording audio using thestart()method. - A message is printed to the console to inform the user that recording has begun and that they can press Ctrl+C to stop the recording.
- A listener is added for the ‘SIGINT’ event (usually triggered by pressing Ctrl+C), which stops the
micInstance, prints a message indicating that recording has finished, and resolves the Promise. - An error listener is added to the
micInputStream. If an error occurs during recording, the Promise is rejected with the error.
When this function is called, it records audio from the user’s microphone and saves it to the specified file. The recording process can be stopped by pressing Ctrl+C, at which point the Promise will resolve, allowing further processing of the recorded audio.
Step 5: Create the transcribeAudio function
This function takes the filename of the recorded audio and transcribes it using OpenAI’s Whisper Speech-to-Text API.
// Transcribe audio
async function transcribeAudio(filename) {
const transcript = await openai.createTranscription(
fs.createReadStream(filename),
"whisper-1"
);
return transcript.data.text;
}
This transcribeAudio function is responsible for transcribing a recorded audio file using OpenAI’s Whisper API. The function accepts a single parameter, filename, which specifies the name of the file containing the recorded audio. Here’s a breakdown of the function:
- The function is defined as an
asyncfunction to allow the use of theawaitkeyword for asynchronous operations within the function. - The
transcribeAudiofunction takes the filename parameter and creates a readable file stream using thefs.createReadStream(filename)method. This stream is then passed to theopenai.createTranscription()method along with the model ID “whisper-1”. - The
openai.createTranscription()method is an asynchronous function call that sends the audio data to OpenAI’s Whisper ASR API for transcription. Theawaitkeyword is used to wait for the transcription API call to complete and return the transcript object. - The returned
transcriptobject contains adataproperty, which in turn has atextproperty that holds the transcribed text. - The function returns the transcribed text (
transcript.data.text) as its final output.
When this function is called with a valid audio file, it sends the audio data to the Whisper Speech-To-Text API and returns the transcribed text as a string.
Step 6: Implement the main function
Create the main function that calls the recordAudio and transcribeAudio functions:
async function main() {
const audioFilename = 'recorded_audio.wav';
await recordAudio(audioFilename);
const transcription = await transcribeAudio(audioFilename);
console.log('Transcription:', transcription);
}
The main function is the primary entry point for the Node.js application, orchestrating the recording and transcribing processes. The function is defined as async to support the use of await for asynchronous operations. Here’s a step-by-step explanation of the function:
- The
audioFilenameconstant is defined and set to'recorded_audio.wav'. This will be the name of the file where the recorded audio will be stored. - The
awaitkeyword is used to call therecordAudio()function and wait for it to complete before moving on. This function records the user’s audio input and saves it as a file with the name specified byaudioFilename. The recording process can be stopped by pressing Ctrl+C. - Once the audio recording is complete, the
transcribeAudio()function is called with theaudioFilenameas its argument. The function sends the audio data to the Whisper Speech-to-Text API and returns the transcribed text. Theawaitkeyword is used to wait for the transcription process to complete. - The transcribed text is stored in the
transcriptionconstant. - Finally, the transcribed text is printed to the console with the label “Transcription:“.
When the main function is executed, it records audio input from the user, transcribes it using OpenAI’s Whisper API, and displays the transcribed text on the console.
Complete code of app.js
Finally, let’s again take a complete code which should now be available in app.js:
const fs = require("fs");
const ffmpeg = require("fluent-ffmpeg");
const mic = require("mic");
const { Readable } = require("stream");
const ffmpegPath = require("@ffmpeg-installer/ffmpeg").path;
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: "YOUR_OPENAI_API_KEY",
});
const openai = new OpenAIApi(configuration);
ffmpeg.setFfmpegPath(ffmpegPath);
// Record audio
function recordAudio(filename) {
return new Promise((resolve, reject) => {
const micInstance = mic({
rate: "16000",
channels: "1",
fileType: "wav",
});
const micInputStream = micInstance.getAudioStream();
const output = fs.createWriteStream(filename);
const writable = new Readable().wrap(micInputStream);
console.log("Recording... Press Ctrl+C to stop.");
writable.pipe(output);
micInstance.start();
process.on("SIGINT", () => {
micInstance.stop();
console.log("Finished recording");
resolve();
});
micInputStream.on("error", (err) => {
reject(err);
});
});
}
// Transcribe audio
async function transcribeAudio(filename) {
const transcript = await openai.createTranscription(
fs.createReadStream(filename),
"whisper-1"
);
return transcript.data.text;
}
// Main function
async function main() {
const audioFilename = "recorded_audio.wav";
await recordAudio(audioFilename);
const transcription = await transcribeAudio(audioFilename);
console.log("Transcription:", transcription);
}
main();
Running The Application
Run the app using:
node app.js
The app will start recording audio. Press Ctrl+C to stop the recording. Once the recording is stopped, the app will transcribe the audio using OpenAI’s Whisper API and print the transcription to the console.
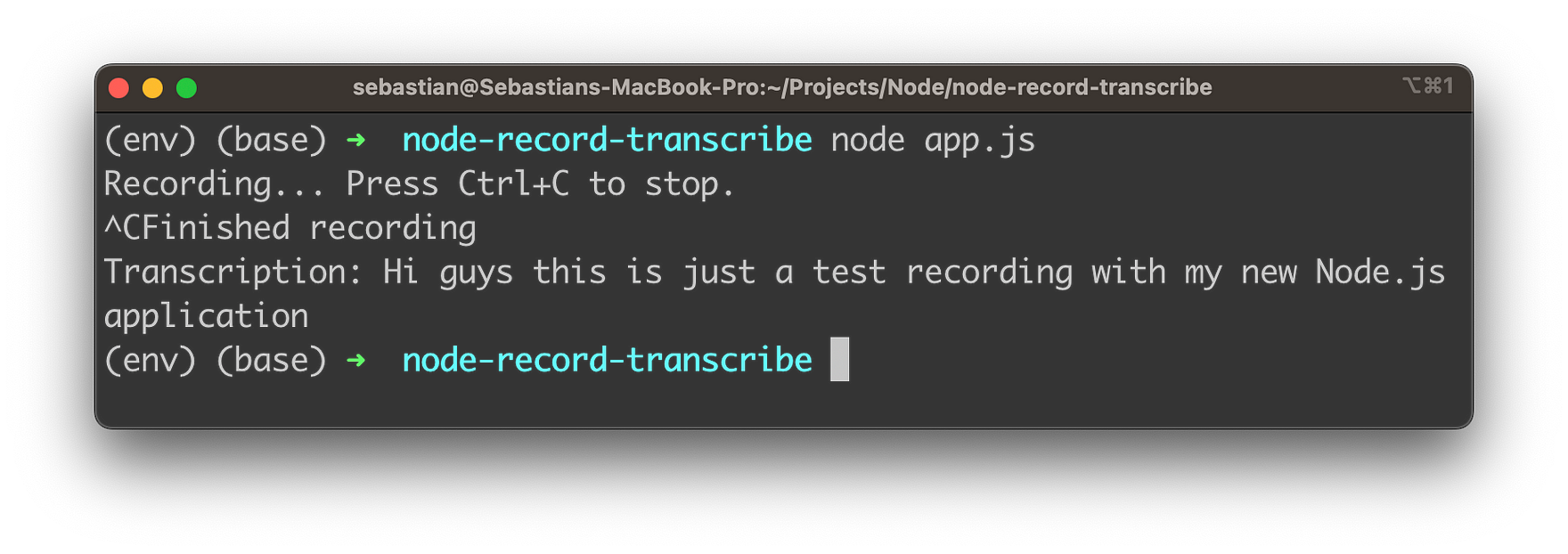
By following these steps, you’ve successfully built a Node.js application that records and transcribes audio using OpenAI’s Whisper Speech-to-Text API. This powerful tool can be customized and adapted for a wide range of applications, opening up new possibilities for enhancing your projects and exploring the exciting world of AI-driven applications.